State Space and Mamba
·The video explained how state space = RNNs + CNNs
Referenced video
It explained with respect to LLMs and how state space makes them faster.
So what it explained :
It took the example of car repair and related it to RNN equations. and converted all RNNs equations in terms of input and output variables. And all the equations can be expressed as convolutions of state space matrices with inputs.
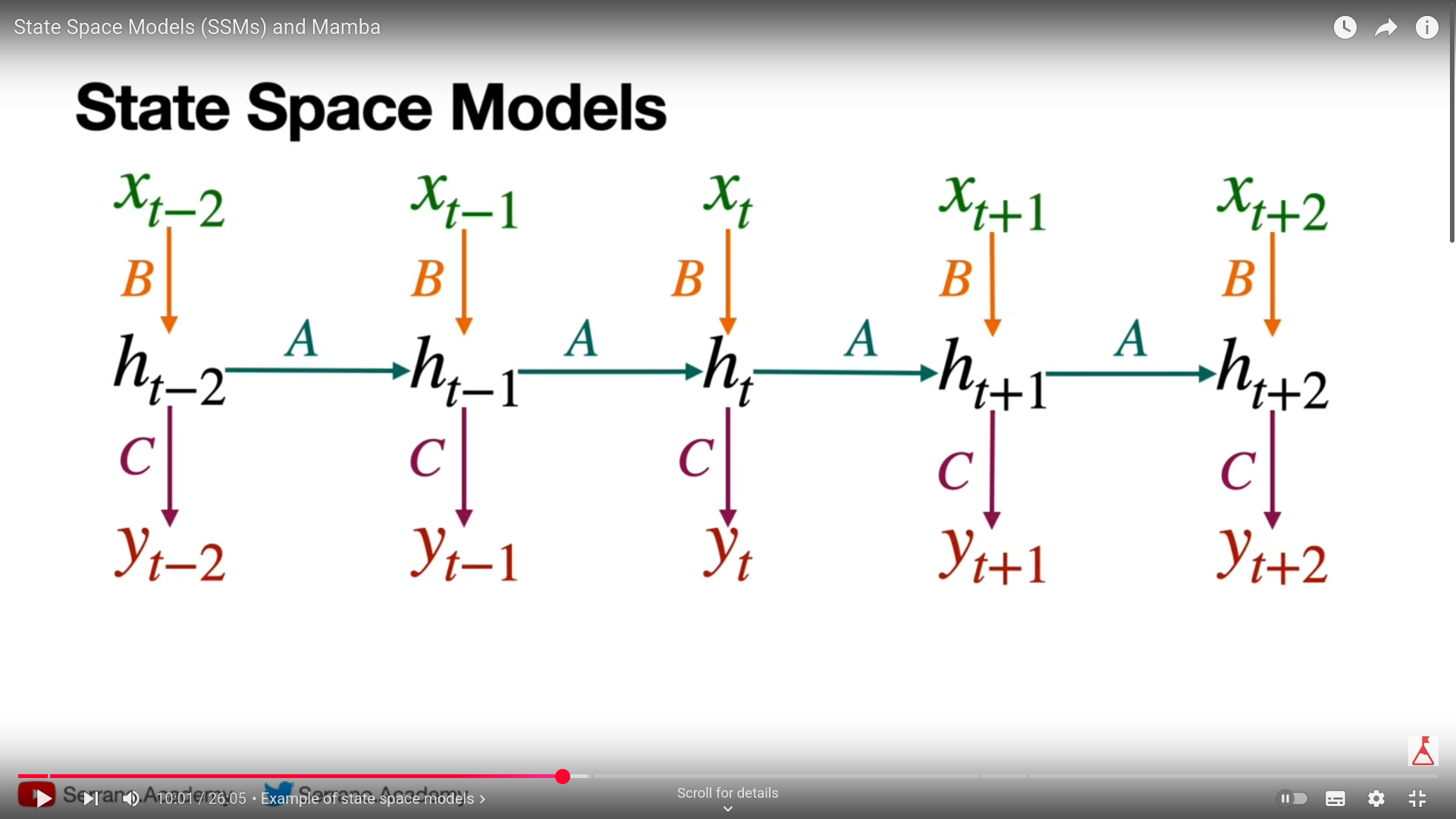





Those convolutions are what making SSMs faster than RNNs.
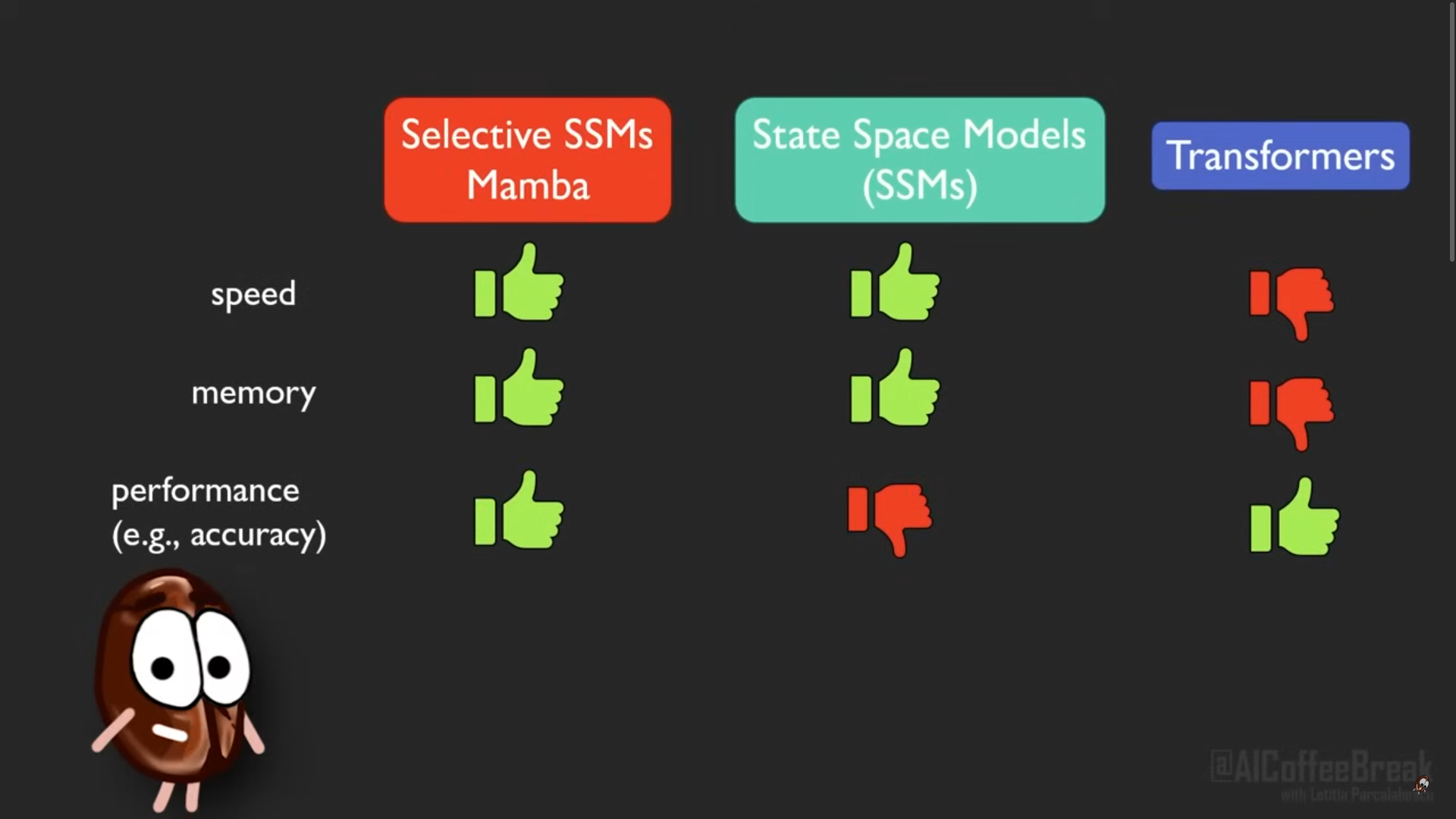
What is mamba :
Paper reference Mambas are selective SSMs. “Selective SSMs introduce attention-like behavior by dynamically selecting or modulating token updates based on the input. While traditional SSMs use static parameters (A, B, C), selective SSMs make these updates input-dependent. This allows them to prioritize certain tokens over others, similar to attention, and enables effective learning through backpropagation.”
What is Backpropagation Doing in Selective SSMs?
Backpropagation doesn’t directly “update the tokens.”
It updates the model parameters — including:
-
Gating parameters
-
SSM parameters (A, B, C in a learnable form)
-
Layer norms, linear layers, etc.
The tokens get modulated (e.g., gated or filtered) as part of the forward pass — the learned parameters decide how they’re modulated.
Here is the structure of the Mamba :

What is the difference between the Mamba and SSMs :
Mamba, like Flash Attention, attempts to limit the number of times we need to go from DRAM to SRAM and vice versa. It does so through kernel fusion which allows the model to prevent writing intermediate results and continuously performing computations until it is done.

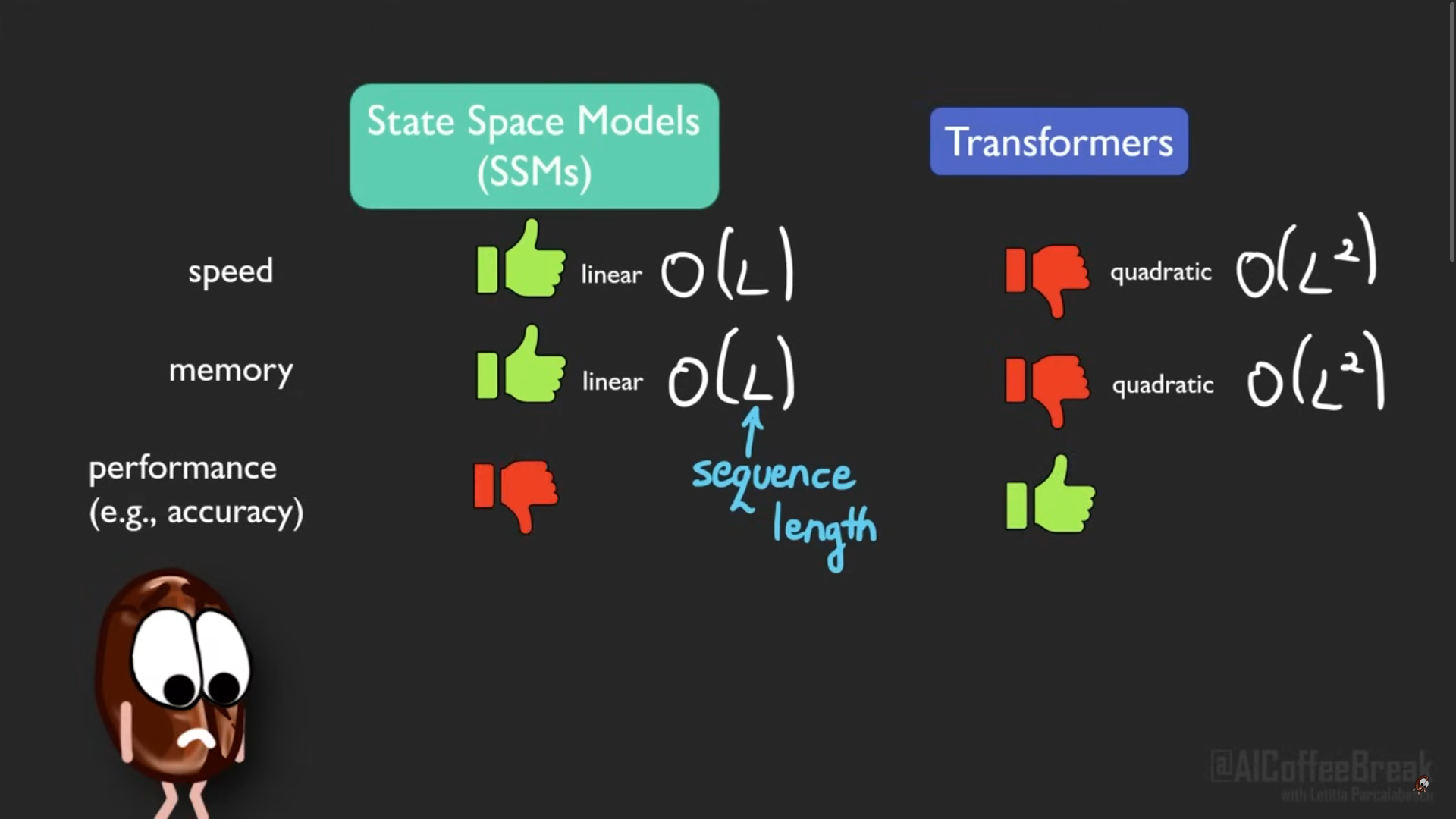
Transformer vs SSMs :
how much efficiency related to time, memory and GPU computational cost can we expect with state space. Since the SSMs dont have to save big attention matrics therefore they are linear in memory. And in terms of speed they are linear therefore good for long length sequences. And as described earlier above about Mamba, they improved the performance specially for vision problems.