Reinforcement Learning
·I first came across to the introduction of reinforcement learning through the cohort conducted by Ajay Shenoy. He gave an example about reinforcement learning with a sentence like “The quick brown fox jumps over the lazy dog”. If you break the sentence and give one part of sentence to a human and gives 10 options (I am giving 3) : the quick brown fox jumps over A) the lazy dog B) the brown bread C) the blue whale
then you quickly can guess the answer. Same is with machine. The machine sees this example so many times. it is called supervised learning. In RL, instead of being told the correct answer, the model would explore different options and get rewarded (say +1 if correct, 0 if not).
Another example that he gave was of chatgpt. When it asks to choose an option from one of two it trains itself for the preference you give it everytime.
My father once asked me if the chatgpt can learn to understand the human behaviour so I think yes with reinforcement learning it can learn the preferences of humans but through feedback. It doesn’t truly “understand” human behavior the way humans do. It’s not developing empathy or self-awareness. But it’s optimizing patterns of responses that are statistically more likely to please humans, based on past feedback.
When grok started verbally bad mouthing (😛) the user in reaction of users bad words is another example of reinforcement learning. It’s just that it was trained or fine-tuned to adopt a more edgy persona — not that it dynamically learned that from just one user.
These are few examples that came to my mind regarding reinforcement learning. I tried to learn the difference of RL from other learning methods in real world.
One solid example of reinforcement learning is cooking. You learn how to cook by trial and error. Where there are certain rules but instead of following deterministic rules, a policy (strategy) is trained based on feedback (taste).
Formal definition of reinforcement learning : Reinforcement Learning (RL) is a framework where an agent learns to take actions in an environment by receiving feedback (rewards or penalties). Over time, the agent updates its policy (decision-making strategy) to maximize expected reward.
It follows the Markov decision process. In markov decision process there is one rule to follow : The future state depends only on the present state and action, not on the history.
So there are states s ∈ S, actions a ∈ A and rewards r ∈ R. States define the situation. reward is the feedback and actions is the agents output.
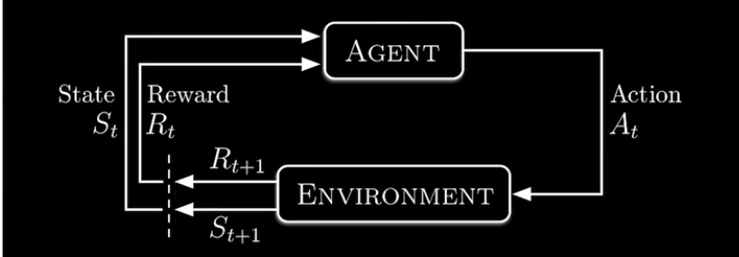
Now according to the Markov property :
p(s′,r∣s,a)=Pr(St+1=s′,Rt+1=r∣St=s,At=a)
Now comes policy what action is taken by the agent in particular situation. ie.
π(a∣s)=Pr(At=a∣St=s)
Initially this probability is uniformally distributed
Then comes the goal on the basis of which the policy is updated. It is the maximization of the expectation of the sum of rewards (feedbacks). ie.
max Eπ[Gt] where $Gt$ is sum of rewards.
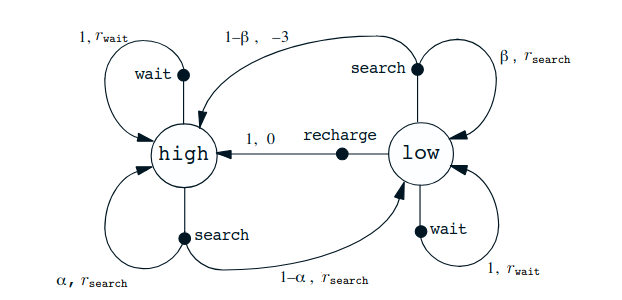
Example of RL as a case of recycling robot :
MDP Definition
- States S : {High, Low}
- Actions A : {Search, Wait, Recharge}
- Transition probabilities: defined by probabilities of finding cans, losing energy, or being given cans.
- Rewards R : +1 for cans, 0 otherwise.
If the energy level is high, then a period of active search can always be completed without risk of depleting the battery. A period of searching that begins with a high energy level leaves the energy level high with probability α and reduces it to low with probability 1 − α. On the other hand, a period of searching undertaken when the energy level is low leaves it low with probability β and depletes the battery with probability 1 − β. In the latter case, the robot must be rescued, and the battery is then recharged back to high. Each can collected by the robot counts as a unit reward, whereas a reward of −3 results whenever the robot has to be rescued. Let rsearch and rwait, with rsearch > rwait, respectively denote the expected number of cans the robot will collect (and hence the expected reward) while searching and while waiting. Finally, to keep things simple, suppose that no cans can be collected during a run home for recharging, and that no cans can be collected on a step in which the battery is depleted. This system is then a finite MDP, and we can write down the transition probabilities and the expected rewards, as in Table 3.1.
 where s is previous state, a is the action taken and s’ is next state. expected reward for that transition is r(s,a,s’) and p(s’|s,a) is the transition probability.
where s is previous state, a is the action taken and s’ is next state. expected reward for that transition is r(s,a,s’) and p(s’|s,a) is the transition probability.
Value functions
There are two kinds of value function which define how good it is for the agent to be in a given start after following the policy ie what is the expected return.
First is state value function that defines the value in the given state when the policy is followed
vπ (s) = Eπ[Gt | St = s]
Second is the action value function ie the value of taking action a in state s under a policy
qπ (s, a) = Eπ[Gt | St = s, At = a]
Solving a reinforcement learning task means, roughly, finding a policy that achieves a lot of reward over the long run. For finite MDPs, we can precisely define an optimal policy in the following way. Value functions define a partial ordering over policies. A policy π is defined to be better than or equal to a policy π0 if its expected return is greater than or equal to that of π0 for all states. In other words, π ≥ π0 if and only if vπ(s) ≥ vπ0(s) for all s ∈ S. There is always at least one policy that is better than or equal to all other policies. This is an optimal policy.
How it can be used in computer vision?
In the paper “Synthetic Sample Selection for Generalized Zero-Shot Learning”, the feature generator generates features that the selector module ranks based on the seen class classifier’s performance. The selector is updated based on the performance of the classifier on the selected features. This is the example of RL to select the augmented features that look real.
In most audio visual navigation papers, mostly RL is used where the goal is to reach a destination and policy is updated how closer the agent reaches to the goal after every action.
Last interesting thing that mentioned in the source is
👉 “RL behaves like supervised learning when there is generalization” → In the sense that once the agent has explored and collected enough data, the final policy network is just a function approximator mapping states to good actions. Evaluating it on unseen states looks the same as testing supervised learning on unseen examples. But RL ≠ SL because getting the training data itself (via exploration and reward signals) is the hard part that supervised learning bypasses.
sources used : Refrenced video Standford notes